


















“人工智能+医学影像”炒作的背后





人工智能及其发展历程

大英百科全书关于人工智能的解释
人工智能时代最初开始于20世纪50年代,数学家艾伦·图灵(Alan Turin)提出了一个简单的问题:“机器能思考吗?(Can a machine think?)”对人工智能的这种定义引起了许多争论,甚至在80年后,对人工智能领域的任何单一定义都不被普遍接受。虽然人工智能的核心是计算机科学的一个分支,但它正变得越来越跨学科,包括从材料科学到航空、电路设计到温室技术、精确健康到汽车技术等领域。

AI之父-数学家艾伦·图灵(1912-1954)
1954年,人工智能最初是从复杂的数学问题解决、逻辑定理的证明和编码信息的解密开始的,并在IBM实验中演示了机器翻译,在国防相关应用中,人工智能在相当长的一段时间内保持在狭窄的可用范围内。从1973年开始,人工智能经历了几年的“人工智能冬天(AI-winter)”,这是由英国科学研究委员会的数学家詹姆斯·莱特希尔教授(Professor Sir James Lighthill)撰写的报告“人工智能:一项总体调查(Artificial Intelligence: A General Survey)”引发的,他对人工智能表示了极大的失望,他说现有的人工智能技术只在一项研究中有效但在现实环境中是不够的。

此后,媒体的悲观情绪,导致资金严重削减,导致人工智能研究终止。
是什么让人工智能在90年代再次流行起来?
90年代,人工智能被引入大型工业专家系统,并取得了巨大的商业成功,特别是在机器翻译、数据挖掘、搜索引擎和机器人技术方面。
虽然人工智能在商业上取得了成功,但它是从大型工业自动化开始的,在目前,人工智能已经通过一些成功的产品和应用开始了我们的日常生活,这些产品和应用来自Siri(Apple, Cupertino, CA)和Alexa(Amazon, Seattle, WA)等虚拟数字助理,帮助我们查找信息和安排约会,自动驾驶汽车(Tesla, Palo Alto, CA; Uber, San Francisco, CA; Waymo [Google spin-off], Mountain View, CA)。亚马逊的交易性人工智能购物引擎是另一个成功案例,它已经存在了相当长的一段时间,并导致了生产力的天文数字增长。

人工智能的基础是数学和计算机科学,但目前人工智能在工业和研究领域的名气建立在以下三个支柱上(下图):
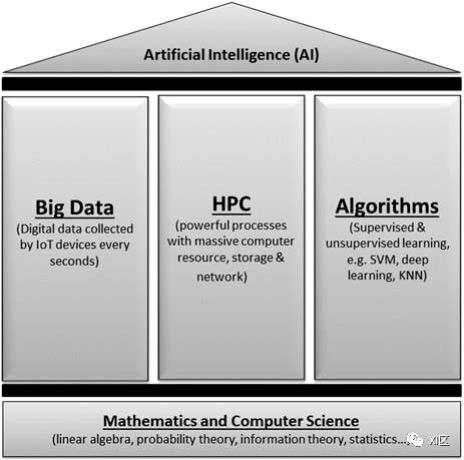
人工智能的三大支柱:大数据、高性能计算和算法
(1)大数据:数据集正在迅速增长,因为它们现在被廉价且众多的信息传感设备(如移动设备、航空相机、麦克风、无线电频率读取器和无线传感器网络)收集。每个人大约每秒贡献2 MB的数据,这些数据可能用于训练人工智能算法。采用深度学习技术对复杂任务进行充分的人工智能建模需要大量的异构训练数据集,才能充分利用模型中大量的可自由训练参数,这些参数可以运行数百万次。经验法则是,人工智能模型需要10倍的数据量来训练与参数数量有关的数据。因此,人工智能和大数据现在似乎密不可分。
(2)高性能计算(HPC)基础设施:计算资源和内存有限的本地计算基础设施无法处理如此大的数据集。人工智能算法需要跨越计算机、网络和存储的强大处理能力,当计算资源最接近数据来源时,其收益最高。这是早期人工智能应用的一个限制因素,当时人工智能只被少数足智多谋的人捕获。随着各大公司纷纷推出HPC云计算,用超大数据集训练人工智能算法已经成为来自家庭环境的广大用户可以实现的目标。事实证明,HPC是人工智能适应和科学发现领域的游戏变革者。
(3)算法:真正的人工智能的能力来自机器学习(ML)算法,它可以大致分为有监督和无监督学习算法。监督学习是指从训练数据集中学习关联的过程,其中算法学习映射函数(y=f(x)),该映射函数将输入变量(x)映射到输出变量(y)。支持向量机(SVM)和逻辑回归等模型属于有监督学习的范畴。在无监督学习中,只要给定输入变量(x),算法就可以探索数据的内部结构。当模型学习数据空间的结构而不学习与目标结果的关联时,K近邻和K均值可以被归类为无监督学习算法。随着近年来大数据和高性能计算的发展,ML算法变得越来越复杂,有数百万个密集连接的处理节点(神经元),它们试图通过多层处理来复制人脑被归类为“深度学习”的功能。深度学习(Deep learning,DL)算法基本上是一类ML算法,具有更强的处理能力,能够感知数据中的非线性结构。

图片源自网络
人工智能在放射科的应用
在数字时代,任何标准医疗中心每天的放射成像检查量都在大幅增长,而接受过培训的阅片者数量保持不变。这在临床实践中造成了一个巨大的瓶颈,极大地增加了放射科医生的工作量。在放射科医生中出现人工智能的主要目的一直是希望通过创建一个自动代理来帮助放射科医生处理日益增加的工作量,该代理可以完成繁琐的任务(例如,体积分析,轮廓、测量、报告)并帮助进行初始图像交互预处理,从而减少工作量。
当前的人工智能应用程序的设计方式是将它们集成到当前的放射工作流程中,其主要目标是通过提高效率、减少错误以及通过由受过培训的放射医生提供的最少的手动输入来帮助放射医生完成日常任务。此外,为推动医学影像人工智能技术的进步,政府也在作出重大努力和政策。在下面的小节中,将重点介绍医学成像中的几种人工智能任务,它们要么是人工智能研究的当前热点,要么已经被人工智能组件成功地解决了,然后是成功的一些核心要素。
人工智能任务与算法
01
分类
人工智能算法最常用的用途之一是用于放射图像分类任务,其中算法以图像(或体积)为输入,并为每个数据集指定一个预定类别(即,鉴别诊断、临床风险),如下图所示。分类模型(算法)可大致分为以下几类:

胸片的分类(上)和分割(下)
(1)线性分类和带核分类(classifier with kernel)-不带kernel的线性分类基于图像特征(即图像特征强度、形状、纹理)线性组合的值计算分类决策。Logistic回归、支持向量机(Support Vector Machine,SVMs)和感知器(Perceptron)都属于这一类。当特征和目标结果之间的关系可以用线性函数描述时,线性分类是有用的。作为回报,它提供了很好的概率解释,并且可以正则化以避免过度拟合(overfitting),因此可以使用有限的数据进行训练。然而,这些类型的算法并不能捕捉自然复杂的关系(nonlinear decision boundaries,非线性决策边界),这在医学图像分类任务中经常遇到。为了建立这种复杂关系的模型,支持向量机可以使用一种称为“Kernel”的技巧,将特征投影到多维空间中,在多维空间中特征是线性可分的。因此,支持向量机在医学图像分析领域(磁共振、CT、钼靶等)一直是一个非常流行的解决方案,直到最近的深度学习取得成功。
(2)基于树的方法和提升方法(boosting)-这些方法背后的核心思想是基于一组分裂规则将数据空间分层或分段,这些规则可以表示为一棵树,例如决策树方法。基于树的算法的输出很容易解释,因为它是由规则明确的;但是,一棵树通常无法识别区域之间的复杂边界。提升方法(XGBoost)和装袋算法(RandomForest)构建了多棵树,然后将它们组合起来产生单一的一致性预测。这些方法已经成功地应用于一些具有挑战性的任务,例如,阿尔茨海默病的磁共振容积分类、肺结节分类、精神分裂症分类。
(3)深度神经网络(DNN)-支持向量机、随机森林和XGBoost分类通常不读取完整图像(或体积)作为输入;相反,它们使用通过应用几种图像特征提取算法(如纹理-Gabor、Riesz)获得的手动设计特征(hand-crafted features)。图像特征工程需要人类的严格监督,通常需要在精确性和计算效率之间找到正确的平衡点的极端专业知识。对于DNNs,特征是从原始图像中自动学习的,并在多个层次上分层表示;然而,这伴随着需要大量数据和计算能力的成本。
随着开源标记X射线图像档案(如NIH ChestX-ray14, Open-i)可用性的增加,已经开发了几种高性能DNN分类算法,用于检测常见的胸部疾病。Yao等人提出了两种深度学习结构的组合:卷积神经网络(CNN)和递归神经网络(recurrent neural network),以利用胸部数据集中的标签依赖性。Rajpurkar等人提出了使用DenseNet-121进行精细调谐的转移学习,这使得胸部X光片上的曲线下区域更大,用于多标签分类。

02
分割
分割也可以被视为监督分类的特殊情况,其中目标是为每个像素分配一个分类标签。CNN—一种深度学习方法被成功地转化为一个完全卷积的网络,该网络通过上采样产生像素级分类图作为输出,解决图像分割问题。然而,在医学图像处理中,稍微修改的全卷积网络UNet(多个上采样层)是最流行的解决方案,因为它使用较少的训练图像并产生更精确的分割(下图)。UNet已被应用于各种超声、MR和CT图像的分割。

基于CNN的分割架构:FCN(上图),UNet(下图)
03
异常检测
在医学影像应用中,阴性数据集和阳性数据集之间的不平衡以及阳性数据集中疾病程度的可能变化给学习算法带来困难,因为结果将偏向于最大的组。对于异常检测任务,训练算法将数据样本显示为异常或非典型。异常检测也可以看作是只有一个输出类的分类的一种特殊情况,使用异常检测算法仅通过对异常的训练来解决数据集不平衡的问题。与需要为每个特定输出标签提供大量训练数据的分类任务不同,异常检测算法可以在相对较小的数据集上进行训练。
然而,这些算法仅能识别数据集是否属于此标签,而无需进一步说明。在MURA数据库中,Wei等人的这项研究给出了异常检测的一个例子,其中包含40561张肌肉骨骼射线照片的图像,其中每项研究都手动标记为正常或异常。一个169层的DenseNet基线模型,扩展了前面提到的ResNet,被用来检测和定位异常。
04
去噪
去噪算法是用来创建一个干净的数据样本,给定一个损坏的数据样本作为输入。在训练阶段,干净的样本作为期望的输出,而噪声版本作为输入。去噪算法可以在优化低图像质量设置下拍摄的图像质量以减少辐射剂量方面发挥作用。在医学成像中,CNNs被用于低剂量CT扫描中的噪声抑制,提高了图像质量,使其与标准剂量CT相当。通过使用低剂量CT作为输入,CNNs的使用可以创建与标准剂量输出CT图像相等的CT图像。

用不同方法处理的图像比较。(a) NDCT, (b) LDCT, (c) TV-POCS, (d) K-SVD, (e) BM3D, (f) KAIST-Net, (g) SSCN, (h) SCN.
Du W , Chen H , Wu Z , et al. Stacked competitive networks for noise reduction in low-dose CT. PLoS ONE, 2017, 12(12):e0190069.

(a)20%剂量FBP重建ILD和(b)相应的动脉钙化(CAC)评分蒙片,(c)20%剂量发生器G3重建G3(ILD)和(d)相应的CAC评分蒙片,(e)20%剂量发生器红外重建IRD和(f)相应的CAC评分蒙片,以及(g)常规剂量FBP重建IRD和(h)相应的CAC评分蒙片。所有图像的窗口级别/宽度为90/750 HU。CAC评分模板显示所有大于130HU的体素为黑色,通过CAC评分选择的体素为红色。
Wolterink J M , Leiner T , Viergever M A , et al. Generative Adversarial Networks for Noise Reduction in Low-Dose CT. IEEE Transactions on Medical Imaging, 2017, 36(12):2536-2545.
每种算法都有各自的优缺点,需要根据具体任务选择最优算法。根据任务和数据的不同,导致特定人工智能模型的最佳选择的考虑因素是基于认知和计算复杂度、期望精度、可扩展性和算法的可解释性。
05
成功的核心要素:数据

数据是人工智能成功的核心要素
训练算法所依据的数据的质量和数量是决定算法性能和可推广性的两个重要因素。尤其是用于成像相关任务的主要人工智能算法之一CNNs,本质上需要大量的数据才能达到最佳性能。然而,根据地理位置、图像系统制造商和个人喜好,目前正在使用各种各样的协议。再加上各大洲、国家甚至医院之间的人口差异,这种差异导致ML算法充分性能所需的数据集数量急剧增加。由于当前的隐私法和存储/共享能力,缺乏足够大的数据集来训练和验证人工智能算法以最佳地执行其任务。为了填补人工智能工作流程中的这一空白,一些倡议正在启动,它们将来自世界各地多个机构的数据库进行合并和创建。第二,数据集相关,限制因素是数据的质量。在医学成像领域,许多分析都是在视觉评估的基础上进行的,导致了较高的等级间变异性,从而导致了对ML算法的参考标准的偏差。为了进一步优化医学成像人工智能算法的工作,一致可靠的参考标签至关重要。
人工智能在心胸成像中的作用

斯坦福大学基于深度神经网络的X光诊断算法。该算法用ChestX-ray14数据集来训练。
另一组在放射学中进行的胸部检查是胸部CT。随着大规模肺癌筛查项目的增加,这类检查尤其增多。大型肺癌筛查试验已经证明可以降低肺癌相关死亡率。预计,在这些结果的基础上,美国和欧洲国家将开始大规模筛查。这些增加的胸部CT检查需要大量的资源,而人工智能应用可以帮助处理增加的工作量和减少假阴性读数。2017年,Kaggle Data Science Bowl(KDSB17)专注于预测肺癌风险,因为患者在扫描后一年内被诊断为肺癌的可能性,在肺癌筛查CT检查的基础上,使用CNN的准确率达到94%。与放射科医生相比,人工智能性能被证明是同等或更高的。虽然结节检测可能是胸部CT成像中人工智能研究的最佳记录领域,但人工智能的使用不仅限于结节评估,还可用于诊断和分期慢性阻塞性肺疾病和肺结核,可用于预测吸烟者的急性呼吸窘迫综合征和死亡率。

肺分割示例
Hammack D. Forecasting lung cancer diagnoses with deep learning. arXiv. 2017:1–6.
除了胸部成像外,心脏成像也越来越受到人们的关注。心血管疾病(CVDs)是全球死亡率的一个重要因素。每年共有1790万人死于心血管疾病,占全球死亡人数的31%。由于成像系统本身等硬件系统的技术发展,如成像分析方法的发展,心脏成像领域一直在进行快速创新,允许更复杂的评估形式。随着无创心脏评估在心脏病患者或疑似心脏病患者的临床研究中的作用越来越大,心脏成像领域的检查数量和复杂性也越来越大。随着对模式识别的关注,这一领域固有的成像性质,人工智能具有很大的希望,以帮助这一领域在医学更进一步。

图片源自网络
例如,非创伤性冠状动脉钙化(CAC)评分计算以确定动脉粥样硬化性CVD的存在和程度,因为它已被证明是未来心血管事件的准确危险因素。获得CAC评分的数量正在迅速增加。CAC评分是一项相当简单但耗时的工作,但需要对整个冠状动脉树的钙化斑块进行手工分割和分类。因此,CAC评分是人工智能算法首先要解决的问题之一。研究表明,人工智能不仅可以在专用的CAC采集上进行CAC评分,还可以在用于肺癌筛查的胸部CT上进行CAC评分。图像质量和计算能力的最新进展还允许使用计算流体动力学计算分数流量对CCTA图像上的狭窄进行功能分析储备(FFR)。然而,这种方法需要大量的计算能力和时间密集型。为了能够对CT衍生的FFR进行实时的现场评估,成功地使用了ML。

临床心脏放射学中AI任务的四大类(以实例应用为例)。CAC,冠状动脉钙化;CAD,冠状动脉疾病;CCTA,冠状动脉CT血管造影;EAT,心外膜脂肪组织;FFR-CT,CT血流储备分数;PVAT,血管周围脂肪组织。
Jiang B, Guo N, Ge Y, Zhang L, Oudkerk M, Xie X. Development and application of artificial intelligence in cardiac imaging. Br J Radiol. 2020 Feb 6:20190812. doi: 10.1259/bjr.20190812.
随着CAC评分和CT-FFR等新参数的出现,显示了影像生物标记物在CVD诊断和治疗中的价值,需要开发新的风险分层和预后模型,包括这些影像标记物。由于人工智能算法能够分析大量的特征和数据,能够检测出复杂的关系,因此是建立这些预测模型的理想方法。一些对相对较大数据集的早期研究表明,将临床危险因素和成像参数结合起来,使用ML算法有望达到这一目的。
除了心胸X线和CT,AI在MRI中的应用主要集中在分割任务上,特别是心脏结构分割用于心功能评估。在成功使用DNNs之前,多图谱配准和变形形状模型是最常用的分割技术;然而,目前大多数方法都是基于CNNs。
未来,人工智能软件包将面世,为单一采集的肺部、心脏和骨骼分析提供全面的分析方法。下图给出了其中一个由供应商创建的软件包的示例,该软件包组合了多个人工智能应用程序。

全自动化的人工智能软件程序(AI-Rad Companion Chest CT, Siemens Healthineers)的示例,该程序允许从胸部CT图像进行预先的肺、心脏和骨骼评估。(A)肺结节检测,(B,C)肺气肿量化,(D)冠状动脉钙化和斑块分析,(E)主动脉测量,和(F)骨密度测量。
除了上面讨论的许多与图像相关的应用之外,还有一组人工智能应用有可能帮助医学成像领域。这些算法介入了成像领域的规划和管理。通过使用自然语言处理算法,可以开发用于自动化和结构化报告的应用程序。此外,人工智能算法可用于为放射科医生排定读取列表的优先级并优化工作流程。所有这些应用程序的主要目的都是减少时间和提高效率。
隐 患
近年来,ML/DL算法在众多的医疗保健应用中显示出了优异的性能,这不仅反映在科学出版物中,也反映在临床实践中。尽管关于道德和监管限制的争论不绝于耳,但大量以医疗保健为重点的新软件工具还是获得了FDA的批准。
有趣的是,大多数工具都是为医学图像分析而设计的,其适用范围从分析CT图像进行中风检测(Viz.ai’s Contact, Viz.ai, San Francisco, CA)到从视网膜摄像机图像(IDx-DR, IDx, Coralville, IA)自主检测糖尿病视网膜病变。这些人工智能系统目前在美国各地的许多临床设施(Iowa Health Care, IA, Johns Hopkins, Baltimore, MA, Erlanger Health System, Chattanooga, TN)中使用。IDx-DR溶液目前甚至被用于零售商店(Albertsons grocery),为糖尿病视网膜病变的初步诊断提供了方便。这一广泛的人工智能系统的采用清楚地表明,在医疗保健行业,人工智能是作为一种智能自动化手段引入的,它可以减轻负担,方便地使用诊断工具。

Viz.ai’s Contact, Viz.ai, San Francisco, CA

图片源自网络

图片源自网络
与许多新的创新一样,监管体系正努力跟上创新的步伐。目前,只有很少的监管工作被确定,以帮助处理在临床实践中使用ML算法。直到现在,医生和其他成像专业人员仍然对他们所做的决定负全部责任,即使他们是基于一种ML算法,在这种算法中他们几乎没有洞察力。由于这些决定带来了严重的后果,不能指望相关的成像专业人员愿意冒任何风险。由于法规试图就如何处理这一责任达成共识,医生仍将对其决策负责;因此,提高对这些算法的理解并降低出错风险仍然很重要。
值得注意的是,精心定义、注释的数据库的创建以及特征和人工智能预测的临床解释高度依赖于专业临床医生的努力。
在放射学中,可以区分两种类型的人工智能应用程序,支持应用程序和临床解释应用程序。支持人工智能的应用,如冠状动脉钙的定量,目前由美国食品和药物管理局(FDA)负责,只需要510(k)的批准。以图像临床解释为主要目标开发的人工智能应用需要FDA的上市前批准(PMA),需要临床试验的结果。
实际上,这意味着,对于支持性人工智能应用,制造商只需证明其实质上等同于类似的合法销售应用,而不需要进行人体试验来证明其有效性和安全性。这与PMA批准形成对比,PMA批准需要显示设备在临床环境中对人体的性能的数据,类似于药物的批准过程。这两个过程的不同会产生严重的后果。2005至2009年间,共召回了113台PMA设备,其中70%通过了510(k)流程。与所有使用患者相关信息的医疗应用程序一样,患者隐私是一个重要问题。人工智能应用的发展涉及从电子健康记录、医学图像和实验室结果中提取的大量患者数据。
随着医生对人工智能应用预测的信任度的提高,这些算法的安全性和可靠性变得越来越重要。随着人工智能应用的增加,过去几年来,针对ML模型的对抗性攻击引起了人们的极大兴趣。Thys等人在文章中描述了一个例子,表明小的对抗性补丁会影响使用神经网络进行目标检测的准确性。还有其他错误解释人工智能结果的例子,Cabiza等人清楚地讨论过。

人工智能在心胸成像中的应用前景
心胸成像领域正面临着新的机遇和挑战,如由于癌症筛查项目的增加和心脏检查次数的增加,采集量的增加,这在最近的指南中得到了强烈的推荐。
基于人工智能的应用有望在短期内改善放射学工作流程,提供异常检测的预读数,精确的定量,例如肿瘤体积损伤跟踪和心脏体积和图像优化。人工智能要真正帮助心胸影像学界,有几个问题需要解决。首先,集成到放射工作流程中,患者敏感数据的安全和保护,特别是对于使用云计算(网络安全)的应用程序,以及责任是需要解决的问题。


人点赞

人收藏

打赏









 010-82736610
010-82736610
 股票代码: 872612
股票代码: 872612
 京公网安备 11010802020745号
京公网安备 11010802020745号











