


















16000亿!谷歌发布人类历史首个万亿级模型 Switch Transformer,中国还有机会赶超吗?








01
1)简化稀疏通道

2)高效稀疏通道

3)Putting all together

4)提升训练与微调的技术



02
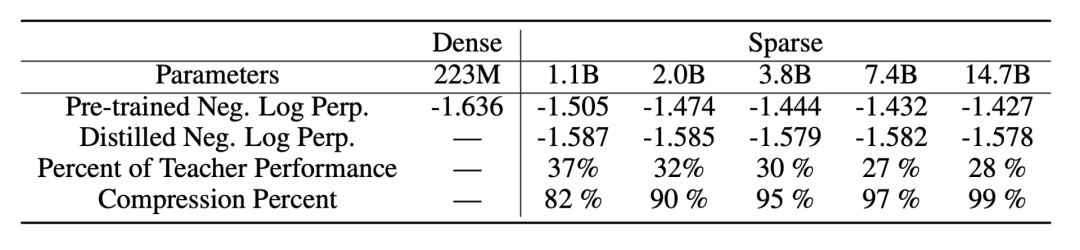
性能对比:稀疏 vs 稠密

 由图可见,在相同负对数复杂度的情况下,Switch-Base的模型(稀疏模型)相比T5-Base模型(稠密模型)要有近七倍的提速。
由图可见,在相同负对数复杂度的情况下,Switch-Base的模型(稀疏模型)相比T5-Base模型(稠密模型)要有近七倍的提速。




03
未来研究可能性
1)六大问题
2)六大可能方向
面对未来更大规模的模型,训练的稳定性是一个重大挑战。作者提到目前的技术对于Switch-Base、Switch-Large和Switch-C模型还没有观察到不稳定现象,但对于更大的模型或许会不够,所以他们提出了使用正则化函数、适度的梯度裁剪等方法作为预备。
训练中存在一些异常现象。一般来说预训练越好,下游任务的效果也就越好,但在一些任务上发现,1.6T参数的Switch-C会比较小模型的结果更低。
Switch-Transformer可以用来研究规模关系,从而来指导融合数据、模型、专家并行的体系结构设计。
这一工作属于自适应计算算法系列,目前使用的是相同的同类专家,但未来可以设计支持异构专家。
调查FFN层之外的专家层,初步的证据表明,这同样可以改善模型质量。
在目前的工作中,主要考虑了语言任务,未来或许可以将模型稀疏性类似地应用到其他模态(例如图像)或多模态中。
04
作者是谁?





本文由作者自行上传,并且作者对本文图文涉及知识产权负全部责任。如有侵权请及时联系(邮箱:nanxingjun@hmkx.cn)
关键词:
谷歌,模型,参数,数据,计算

人点赞

人收藏

打赏









 010-82736610
010-82736610
 股票代码: 872612
股票代码: 872612
 京公网安备 11010802020745号
京公网安备 11010802020745号










