

写给医生的人工智能体验课(五):基于TensorFlow识别MNIST手写数字



MNIST是一个非常有名的手写体数字识别数据集,在很多资料中,这个数据集都会被用作深度学习的入门样例。它是由0 到9 的数字图像构成的。完整的MNIST有训练图像6 万张,测试图像1 万张。在TensorFlow 中,又将原先的60000 张训练图片重新划分成了新的55000张训练图片和5000张验证图片。
所以在mnist 对象中,数据一共分为三部分:mnist.train 是训练图片数据, mnist. validation 是验证图片数据,mnist.test是测试图片数据,这正好对应了机器学习中的训练集、验证集和测试集。
一般来说,会在训练集上训练模型,通过模型在验证集上的表现调整参数,最后通过测试集确定模型的性能。正如上节课展示的一样,每张图片都由一个28×28 的矩阵表示,每张图片都由一个784 维的向量表示(28*28=784),处理后的每一张图片是一个长度为784的一维数组,这个数组中的元素对应了图片像素矩阵中的每一个数字。
要建立更复杂的神经网络,就要用到深度学习框架,例如TensorFlow、Keras、PyTorch、Caffe、MXNet等。这些框架类似于R里面的包,每次使用前都需要导入。一套深度学习框架就是这个品牌的一套积木,各个组件就是某个模型或算法的一部分,你可以自己设计如何使用积木去堆砌符合你数据集的积木。
不同领域选择的框架不同,正如我们做医学统计有人喜欢SPSS、有人喜欢stata,也有人擅长R。一般来说公司要做产品,用TensorFlow多,学术界用PyTorch多。想入门的同学总是会纠结学R还是python,深度学习框架又是选择哪个好。网上有各种各样的声音,但个人觉得最重要的还是你这个领域的人用哪个工具多,这样能更快地找到相关的学习资料。譬如你是要做肿瘤领域的生存分析研究,就没必要先学python了,虽然现在python的广告满天飞……
TensorFlow这种深度学习框架和上节课Scikit-learn、numpy这些传统模块在语法上有一定区别。后者是把变量赋值好再进行运算,而前者是先把复杂的运算结构定义好了,再传入变量。顾名思义,tensor是张量,也就是多维度的数据,flow是流动的意思。Tensorflow就是构建好流程图,让数据在其中流动。后续内容将用TensorFlow 1.14版本开展,建立MNIST的识别模型。TensorFlow需要打开Anaconda Prompt,通过pip install命令安装,具体步骤网上有很多教程。
载入数据后可以看到有四个压缩文件,上面两个是测试集的数据和标签,后面两个是训练集的数据和标签。相比前两节课,本案例的数据量大得多,所以设定一个Batch Size,含义一次训练所选取的样本数,一般为2的n次方。


我们建立一个非常简单的神经网络,只有一个神经元。下面代码把输入和输出输入和输出定义好维度、数据类型,待后面再传入MNIST数据集运算。在一开始的时候,权重W和偏置b都是0,模型的预测值就是W*x+b

这里设定了代价函数和优化算法。对于分类模型,一般选用交叉熵函数。我们在第二节课中用Excel推演过传统的梯度下降,越计算到后面,权重和偏置改变的幅度就越小。
为了弥补传统梯度下降算法的一些缺点,一些衍生的算法诞生了,Adam算法是其中常用的一个。train_step这个运算就是求代价函数的最小值,我们设定一定数量的运算周期,在这期间如果代价函数已经接近最小值,那么权重和偏置就得以确定,模型的预测准确率也达到最高(具体原理看第二篇推文)。

这里correct_prediction是指求预测结果和测试集是否一致,一致就是True,不一致就是FALSE,并形成一个列表。accuracy就是把刚才的列表转换成数值后,再计算平均的准确率。我们希望能看到模型运算一定周期后,最后的准确率能达到多少。


前面的步骤和之前一样

高能预警:从这里开始的代码将具有较大难度,没有基础的同学不太可能一时半会理解这些代码,如果要详细讲透,又需要很长的内容,本次毕竟只是体验课,建议大家不改动代码跑一遍感受一下。我们可以这样抽象地理解这个卷积神经网络:图像是有长、宽、高(通道数),卷积和池化就是用卷积核提取一定区域的性质,把图像的长宽变小,高度变高。图像便从一个大的画板,逐渐浓缩成一个面积小但高度很高的方形柱体。最后把方形柱体的信息释放成一维数据,再和分类对应上。

这次卷积神经网络的结构为:输入层——卷积层1——池化层1——卷积层2——池化层2——全连接层1——全连接层2——输出层,卷积层、池化层、全连接层都属于卷积网络中的隐藏层。x_image是输入层,28,28代表图像的高和宽,1代表颜色通道,第一个数字(-1)为输入的批次,-1代表自动适配。输出通道数可以类比为普通神经网络中的隐藏层神经元数,是可以人为设定的。

28*28的图片第一次卷积后还是28*28,高和宽不变,但是通道数变成32;第一次池化后变为14*14,通道数依然是32。第二次卷积后为14*14,通道数为64,第二次池化后变为了7*7,通道数为64。经过上面操作后,一张图片得到64张7*7的平面,因为设定的批次是64,所以数据的维度变成(64,7,7,64)

最后是两个全连接层的计算。两次卷积和池化后的特征很抽象,无法直接和输出连接起来,全连接层将前面经过多次卷积后高度抽象化的特征进行整合,然后可以进行归一化,对各种分类情况都输出一个概率,之后可以根据全连接得到的概率进行分类。

这部分代码的意义和前文一样。

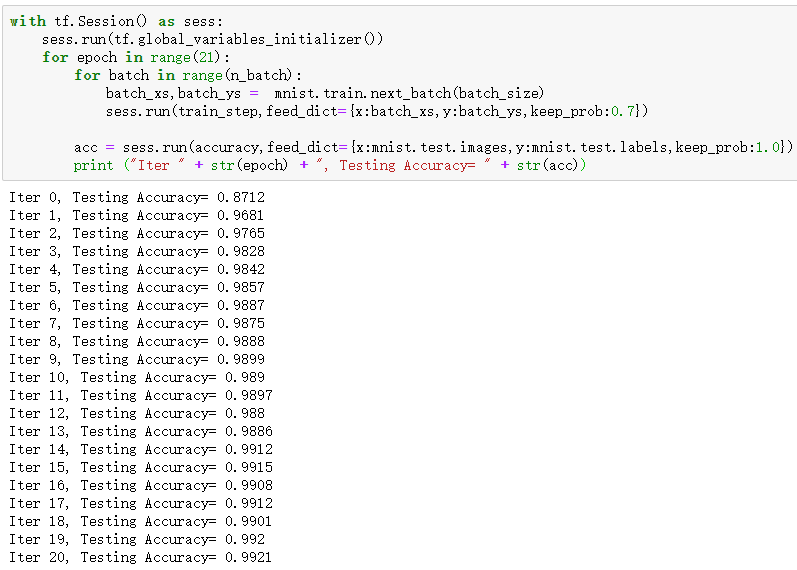
定义好网络结构后,就传入数据开始训练,训练了21个周期之后,准确率达到了99%以上,效果喜人!这就是卷积神经网络的威力!需要一提的是,卷积神经网络的运算量大,TensorFlow默认使用CPU计算,运算时间可能需要耗费几十分钟,开启GPU加速后能缩减到几分钟。我的台式电脑显卡是1080ti,只用了两分钟不到,看来我们有充分的理由购置一块好的显卡来研究深(da)度(xing)学(you)习(xi)了(手动斜眼)。不过配置GPU环境有点麻烦,有兴趣往这方面发展的同学再去深入了解吧~


 打赏
打赏

精彩评论
相关阅读




中国医院排行榜















 010-82736610
010-82736610
 股票代码: 872612
股票代码: 872612





©2012-2019 北京华媒康讯信息技术股份有限公司 All Rights Reserved. 注册地址:北京 联系电话:82736610
 京公网安备 11010802020745号
京公网安备 11010802020745号
